
かなり久しぶりの更新となってしまいました。日経ソフトウェア最新版の企画で、edinetからAPIを使ってXBRL形式のデータを取得し、財務分析を行おうというものです。edinetからデータがダウンロードできることは知っていましたが、面倒なこともありなかなか手が出せずにいました。ちょうどよい企画が来てよかったです。Visual Studioで動かすと日経ソフトウエアの情報そのままだと動かないので、自分なりにカスタマイズしてみた備忘録です。
WebAPIにアクセスするため「Requests」をインストールしてみる
WebAPIにアクセスするためには「Requests」というモジュールをインストールする必要があります。いつもの通りの流れでOKです。
ソリューションのpython環境を右クリックして、すべてのpython環境を表示
matplotlib のときと同様に
それならば、python環境を右クリックして、requestsと検索窓に入力。すべてのpython環境を表示の下のほうに出てくる、
次のコマンドを実行する pip install requestsをクリック
コンソール画面にて正常にインストールできたとあるので、できたみたいです。
早速書いてみる
import requests
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
# 書類一覧から書類管理番号を取得する関数
def get_doc_id(date, edinet_code, doc_type):
# EDINETのAPIを使って書類一覧を取得する
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
docs = requests.get(url, params=params, verify=False)
docs_results = docs.json()['results']
for result in docs_results:
if result['docTypeCode'] != doc_type: # 書類種別コードで抽出
continue
if result['edinetCode'] == edinet_code: # EDINETコードで抽出
doc_id = result['docID'] # 書類管理番号を取得
return doc_id
# 日付、EDINETコード、書類種別コードを指定して書類管理番号を取得する
date = '2022-06-28'
edinet_code = 'E01807' # 「日本電波工業」証券コードじゃない!!
doc_type = '120' # 「有価証券報告書」
doc_id = get_doc_id(date, edinet_code, doc_type)
print(doc_id)サンプルでは任天堂が2022年6月30日に発表した有価証券報告書の書類管理番号を取得するようになっていますが、さすがにそのままぱくるのはよくないので、日本電波工業の有価証券報告書にします。
edinet_codeが証券コードじゃないのはわかりずらい。詳細はedinetの検索画面で確認してから。
とりあえず動かしてみる。
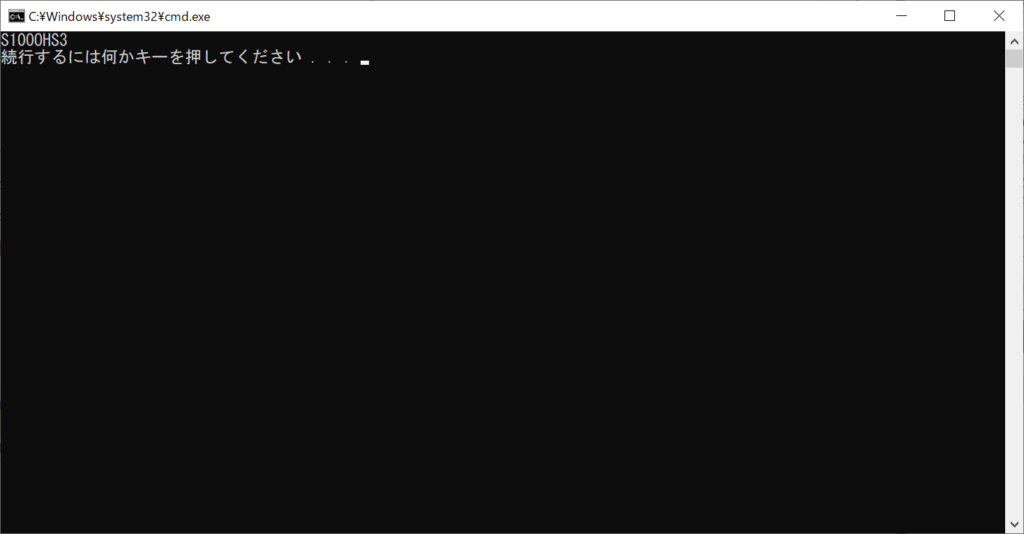
できた。書類IDが取れたみたい。
さらにいじって、zipファイル形式で取得したファイルを解凍してみます。
import requests
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
from pathlib import Path
import zipfile
import os
# 書類一覧から書類管理番号を取得する関数
def get_doc_id(date, edinet_code, doc_type):
# EDINETのAPIを使って書類一覧を取得する
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
docs = requests.get(url, params=params, verify=False)
docs_results = docs.json()['results']
for result in docs_results:
if result['docTypeCode'] != doc_type: # 書類種別コードで抽出
continue
if result['edinetCode'] == edinet_code: # EDINETコードで抽出
doc_id = result['docID'] # 書類管理番号を取得
return doc_id
# 指定した書類管理番号の書類を取得し、zip形式で保存
def download_zip(date, edinet_code, doc_id):
# EDINETのAPIを使って書類をダウンロードする
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
binary_response = requests.get(url, params=params, verify=False)
# 有価証券報告書を保存する「yuho_report」フォルダーを作る
base_dir = Path(__file__).resolve().parent
save_dir_name = 'yuho_report'
if not os.path.exists(Path(base_dir, save_dir_name)):
os.makedirs(Path(base_dir, save_dir_name))
# 書類のファイル名を「日付_EDINETコード」に設定する
file_path = f'{base_dir}/{save_dir_name}/{date}_{edinet_code}'
# 書類をzip形式で保存する
with open(f'{file_path}.zip', 'wb') as f:
for chunk in binary_response.iter_content(chunk_size=1024):
f.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(f'{file_path}.zip') as existing_zip:
existing_zip.extractall(file_path)
#zipファイルを削除 //OK
os.remove(f'{file_path}.zip')
return file_path
# 日付、EDINETコード、書類種別コードを指定して書類管理番号を取得する
date = '2022-06-28'
edinet_code = 'E01807' # 「日本電波工業」証券コードじゃない!!
doc_type = '120' # 「有価証券報告書」
doc_id = get_doc_id(date, edinet_code, doc_type)
file_path = download_zip(date, edinet_code, doc_id)
print(file_path)サンプルにzipを削除する処理を追記。これで少しはきれいになりそう。
Arelle環境をつくる
XBRLを読み解くのに「Arelle」というモジュールを使うのがいいみたいです。
おなじみの環境追加の検索窓から「arelle」と打って、pip install arrellをクリックするとインストールできます。
とインストールしたのはいいのですが、githubからファイルを持ってこなくてはいけないみたい。
https://github.com/Arelle/Arelle
ここから「CODE」をクリックしてファイル群をダウンロードします。
visual studioの場合はpythonの仮想環境の場所が下記となっているので、下記内の「arelle」フォルダを先ほどダウンロードしたファイル群で置き換えます。
C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python37_64\Lib\site-packages
さらに、「regex」「lxml」「isodate」「pyparsing」をインストールします。
エラーが発生…
サンプルの通りに書いたのに
No module named ‘typing_extensions’
と怒られるので、しょうがなくtyping_extensionsをインストール。それでも…
FileNotFoundError: [WinError 2] 指定されたファイルが見つかりません。どういうこと???
いろいろ調べてみるとこの場合は、Arelle の Version.py の一部を、以下のように変更したらいいようです。
インストールフォルダ\arelle\Version.pydef getVersion() -> str:
for version_fetcher in [getBuildVersion, getDefaultVersion]: # getGitHash
# for version_fetcher in [getBuildVersion, getGitHash, getDefaultVersion]: # コメントアウト
fetched_version = version_fetcher()
if fetched_version is not None:
return fetched_version
raise ValueError('Version not set')これでようやく動くようになります。
さあ、日本電波工業の売上高データを取得するぞ…とおもいきや取得できません。どうやら任天堂とフォーマットが違うのか???しょうがないのでいったん任天堂のデータを取得します。
import requests
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
from pathlib import Path
import zipfile
import os
from arelle import Cntlr, ModelManager
from arelle.ModelValue import qname
# 書類一覧から書類管理番号を取得する関数
def get_doc_id(date, edinet_code, doc_type):
# EDINETのAPIを使って書類一覧を取得する
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
docs = requests.get(url, params=params, verify=False)
docs_results = docs.json()['results']
for result in docs_results:
if result['docTypeCode'] != doc_type: # 書類種別コードで抽出
continue
if result['edinetCode'] == edinet_code: # EDINETコードで抽出
doc_id = result['docID'] # 書類管理番号を取得
return doc_id
# 指定した書類管理番号の書類を取得し、zip形式で保存
def download_zip(date, edinet_code, doc_id):
# EDINETのAPIを使って書類をダウンロードする
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
binary_response = requests.get(url, params=params, verify=False)
# 有価証券報告書を保存する「yuho_report」フォルダーを作る
base_dir = Path(__file__).resolve().parent
save_dir_name = 'yuho_report'
if not os.path.exists(Path(base_dir, save_dir_name)):
os.makedirs(Path(base_dir, save_dir_name))
# 書類のファイル名を「日付_EDINETコード」に設定する
file_path = f'{base_dir}/{save_dir_name}/{date}_{edinet_code}'
# 書類をzip形式で保存する
with open(f'{file_path}.zip', 'wb') as f:
for chunk in binary_response.iter_content(chunk_size=1024):
f.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(f'{file_path}.zip') as existing_zip:
existing_zip.extractall(file_path)
#zipファイルを削除 //OK
os.remove(f'{file_path}.zip')
return file_path
# 日付、EDINETコード、書類種別コードを指定して書類管理番号を取得する
#date = '2022-06-28'
#edinet_code = 'E01807' # 「日本電波工業」証券コードじゃない!!
date = '2022-06-30'
edinet_code = 'E02367' # 「任天堂」
doc_type = '120' # 「有価証券報告書」
doc_id = get_doc_id(date, edinet_code, doc_type)
file_path = download_zip(date, edinet_code, doc_id)
# Arelleを使って売上高を抽出するコード
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
# ハードコーディングがださい
#xbrl_file_path = f'{file_path}/XBRL/PublicDoc/jpcrp030000-asr-001_E01807-000_2022-03-31_01_2022-06-28.xbrl'
xbrl_file_path = f'{file_path}/XBRL/PublicDoc/jpcrp030000-asr-001_E02367-000_2022-03-31_01_2022-06-30.xbrl'
model_xbrl = model_manager.load(xbrl_file_path)
ns = model_xbrl.prefixedNamespaces["jppfs_cor"]
qn = qname(ns,name="jppfs_cor_NetSales")
facts = model_xbrl.factsByQname[qn]
for fact in model_xbrl.facts:
jp_label = fact.concept.label()
if jp_label == "売上高" and fact.concept.qname.localName == "NetSalesSummaryOfBusinessResults" and (not "NonConsolidatedMember" in fact.contextID):
print(fact)
model_manager.close()ちょっと時間はかかるけど取得できました。
※なぜ日本電波工業の売上高が取得できないかわかりました。国際会計基準(IFRS)のため、そもそもラベル名が異なるようです。for分のラベル名の判定を以下のようにしてあげればいいです。
for fact in model_xbrl.facts:
jp_label = fact.concept.label()
if jp_label == "売上高" and fact.concept.qname.localName == "NetSalesSummaryOfBusinessResults" and (not "NonConsolidatedMember" in fact.contextID):
print(fact)
if jp_label == "売上高(IFRS)" and fact.concept.qname.localName == "NetSalesIFRSSummaryOfBusinessResults" and (not "NonConsolidatedMember" in fact.contextID):
print(fact)グラフの表示
あとはグラフを書きます。どうも連結決算の場合の項目がうまく取れないので、やっぱり任天堂の情報で取得。あとは考えます。
import requests
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
from pathlib import Path
import zipfile
import os
from arelle import Cntlr, ModelManager
from arelle.ModelValue import qname
import matplotlib.pyplot as plt
# 書類一覧から書類管理番号を取得する関数
def get_doc_id(date, edinet_code, doc_type):
# EDINETのAPIを使って書類一覧を取得する
url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
params = {
"date": date,
"type": 2,
}
docs = requests.get(url, params=params, verify=False)
docs_results = docs.json()['results']
for result in docs_results:
if result['docTypeCode'] != doc_type: # 書類種別コードで抽出
continue
if result['edinetCode'] == edinet_code: # EDINETコードで抽出
doc_id = result['docID'] # 書類管理番号を取得
return doc_id
# 指定した書類管理番号の書類を取得し、zip形式で保存
def download_zip(date, edinet_code, doc_id):
# EDINETのAPIを使って書類をダウンロードする
url = f'https://disclosure.edinet-fsa.go.jp/api/v1/documents/{doc_id}'
params = {
"type": 1
}
binary_response = requests.get(url, params=params, verify=False)
# 有価証券報告書を保存する「yuho_report」フォルダーを作る
base_dir = Path(__file__).resolve().parent
save_dir_name = 'yuho_report'
if not os.path.exists(Path(base_dir, save_dir_name)):
os.makedirs(Path(base_dir, save_dir_name))
# 書類のファイル名を「日付_EDINETコード」に設定する
file_path = f'{base_dir}/{save_dir_name}/{date}_{edinet_code}'
# 書類をzip形式で保存する
with open(f'{file_path}.zip', 'wb') as f:
for chunk in binary_response.iter_content(chunk_size=1024):
f.write(chunk)
# zipファイルを解凍する
with zipfile.ZipFile(f'{file_path}.zip') as existing_zip:
existing_zip.extractall(file_path)
return file_path
# 日付、EDINETコード、書類種別コードを指定して書類管理番号を取得する
#date = '2022-06-28'
#edinet_code = 'E01807' # 「日本電波工業」証券コードじゃない!!
date = '2022-06-30'
edinet_code = 'E02367' # 「任天堂」
doc_type = '120' # 「有価証券報告書」
doc_id = get_doc_id(date, edinet_code, doc_type)
file_path = download_zip(date, edinet_code, doc_id)
# Arelleを使って売上高を抽出するコード
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
xbrl_file_path = f'{file_path}/XBRL/PublicDoc/jpcrp030000-asr-001_E02367-000_2022-03-31_01_2022-06-30.xbrl'
#xbrl_file_path = f'{file_path}/XBRL/PublicDoc/jpcrp030000-asr-001_E01807-000_2022-03-31_01_2022-06-28.xbrl'
model_xbrl = model_manager.load(xbrl_file_path)
ns = model_xbrl.prefixedNamespaces["jppfs_cor"]
qn = qname(ns,name="jppfs_cor_NetSales")
facts = model_xbrl.factsByQname[qn]
sales_list=[]
ordinaryIncome_list=[]
roe_list=[]
per_list=[]
tag_label_list = ["Prior4YearDuration","Prior3YearDuration", "Prior2YearDuration","Prior1YearDuration", "CurrentYearDuration"]
label_list = ["Prior4YD","Prior3YD","Prior2YD","Prior1YD", "CurrentYD"]for fact in model_xbrl.facts:
jp_label = fact.concept.label()
if jp_label == "売上高" and fact.concept.qname.localName == "NetSalesSummaryOfBusinessResults" and (fact.contextID in tag_label_list):
sales_list.append(int(fact.value))
elif jp_label == "売上高(IFRS)" and fact.concept.qname.localName == "NetSalesIFRSSummaryOfBusinessResults" and (not "NonConsolidatedMember" in fact.contextID):
sales_list.append(int(fact.value))
elif jp_label == "経常利益又は経常損失(△)" and (not "NonConsolidatedMember" in fact.contextID) and (fact.contextID in tag_label_list):
if not int(fact.value) in ordinaryIncome_list:
ordinaryIncome_list.append(int(fact.value))
elif jp_label == "自己資本利益率" and (not "NonConsolidatedMember" in fact.contextID) and (fact.contextID in tag_label_list):
roe_list.append(float(fact.value))
elif jp_label == "株価収益率" and (not "NonConsolidatedMember" in fact.contextID)and (fact.contextID in tag_label_list):
#利益がマイナスの時はPERは""なので0とする。
per_list.append(float(fact.value or 0))
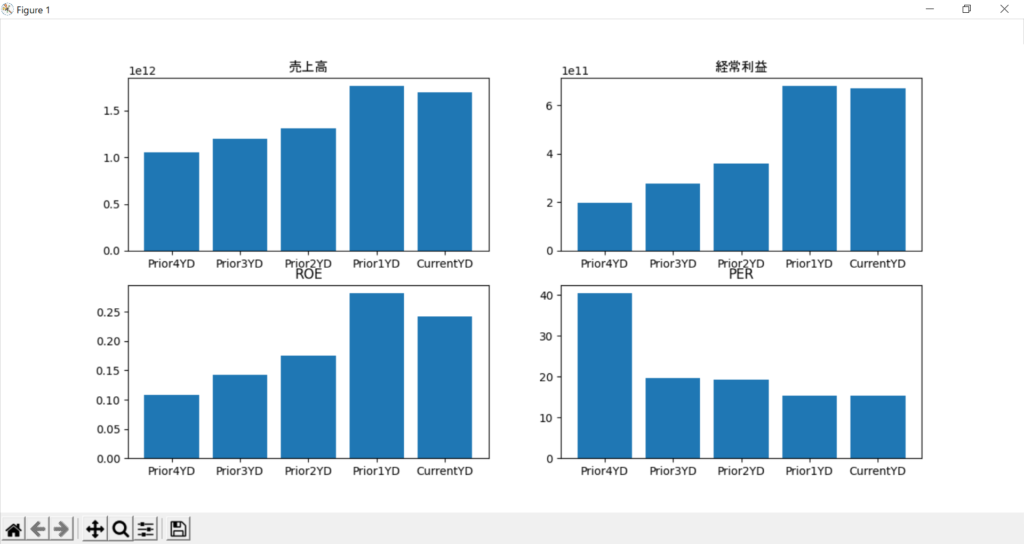
print('売上高:{0}'.format(sales_list))
print('経常利益:{0}'.format(ordinaryIncome_list))
print('自己資本利益率(ROE):{0}'.format(roe_list))
print('株価収益率(PER):{0}'.format(per_list))
fig = plt.figure(figsize=(13,6))
sales = fig.add_subplot(2, 2, 1)
sales.bar(label_list, sales_list)
sales.set_title("売上高" ,fontname="MS Gothic")
ordinaryIncome = fig.add_subplot(2, 2, 2)
ordinaryIncome.bar(label_list, ordinaryIncome_list)
ordinaryIncome.set_title("経常利益",fontname="MS Gothic")
roe = fig.add_subplot(2, 2, 3)
roe.bar(label_list, roe_list)
roe.set_title("ROE")
per = fig.add_subplot(2, 2, 4)
per.bar(label_list, per_list)
per.set_title("PER")
plt.show()
model_manager.close()できた。
文字化け対策
なお、グラフの見出しに日本語を使おうとすると文字化けしてしまうのですが、
ordinaryIncome.set_title("経常利益",fontname="MS Gothic")このように日本フォントを指定してあげると、表示されるようです。
空文字対応
PERがNoneの項目があったため、floatに変換しようとすると怒られました。兄弟ブログにも記載していますが、日本電波工業は以前赤字企業だったため、赤字の場合はPERは正しく表記されません。
強引に0に変換しています。
#利益がマイナスの時はPERは""なので0とする。
per_list.append(float(fact.value or 0))まとめ
とりあえず、Visual Studioで動かしてみるところまではできました。
残る課題は、連結決算・IFRSの場合に若干項目名が違うことと、xbrlのファイル名がハードコーディングしてあるところの改善です。まあここは触りながら進めていきましょう。
